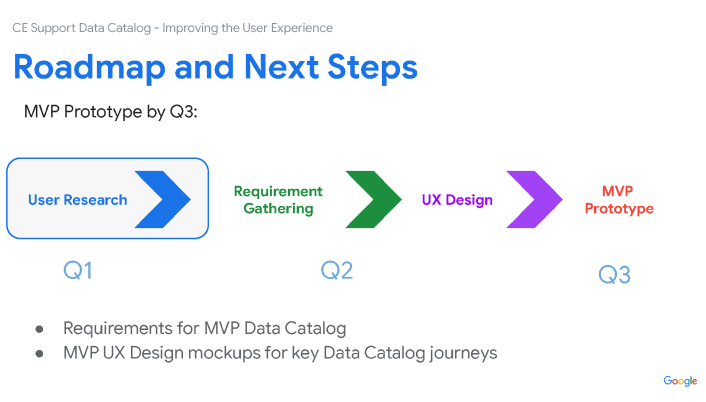
Overview: Redesigning Google's Customer Support Data Catalog
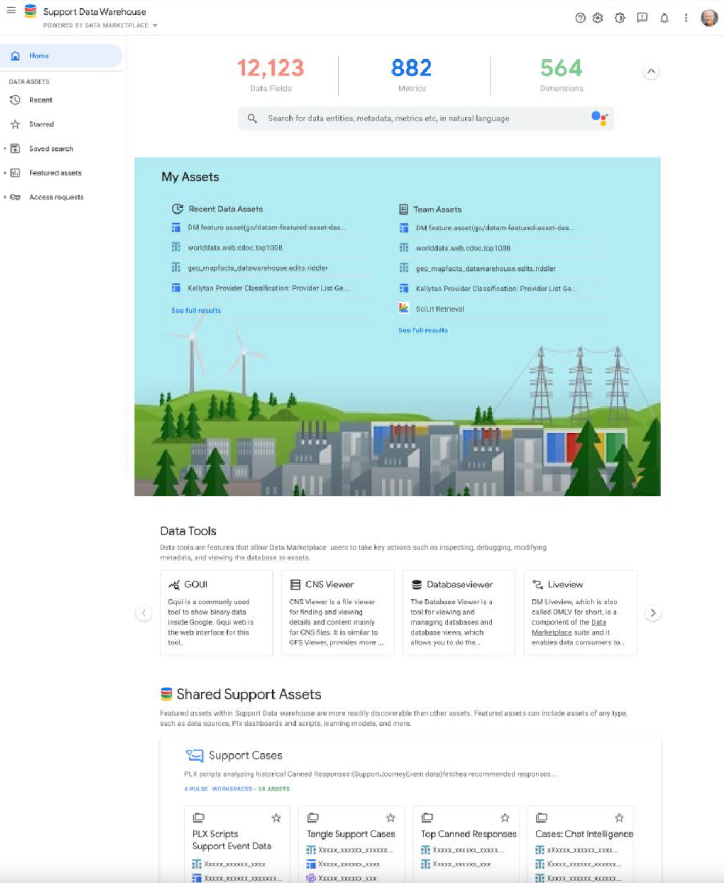
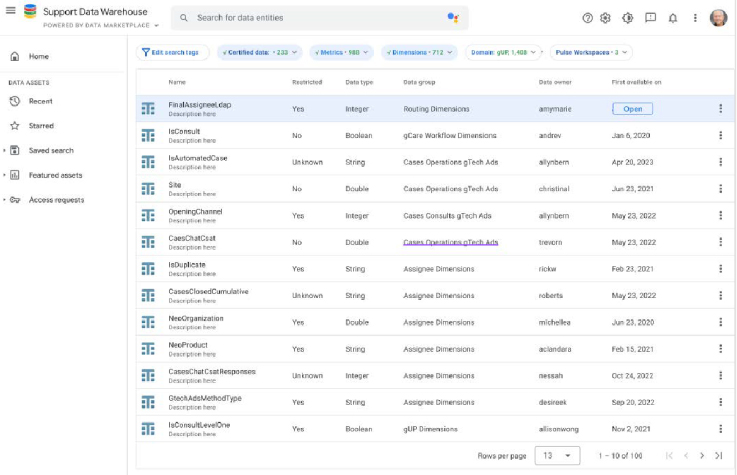
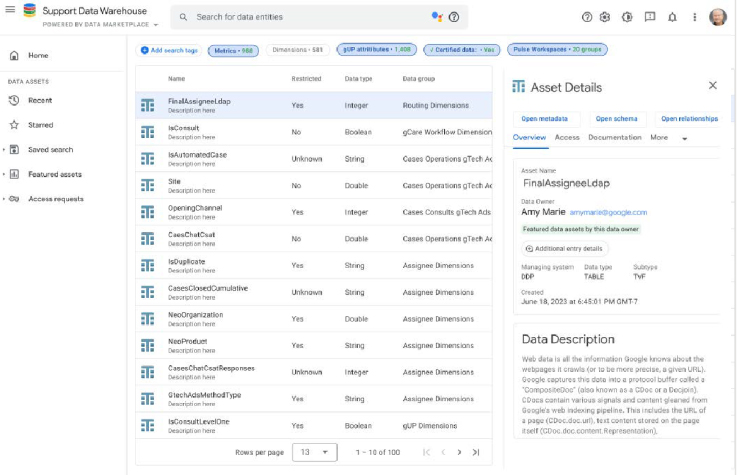
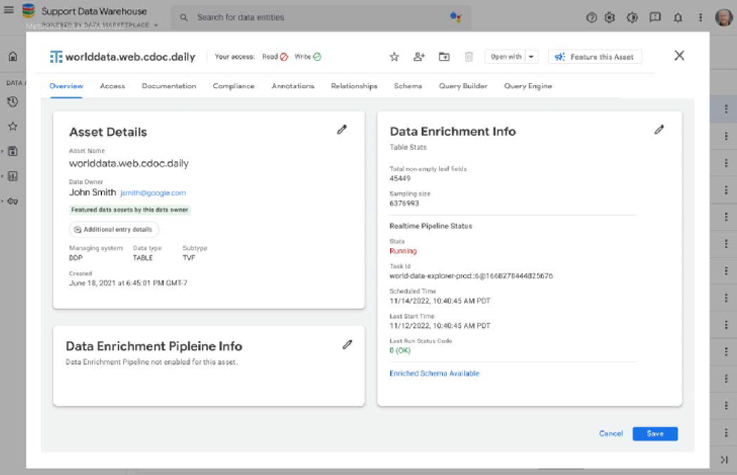
I was hired to redesign Google's Customer Support Data Catalog, with the goal of integrating advanced AI and machine learning technology to streamline the handling of vast customer support data for all Google products, worldwide. The project planned for short and long term improvements by enhancing usability and data discoverability through user-centered design methods and new advanced generative AI vector database and data lake technology.
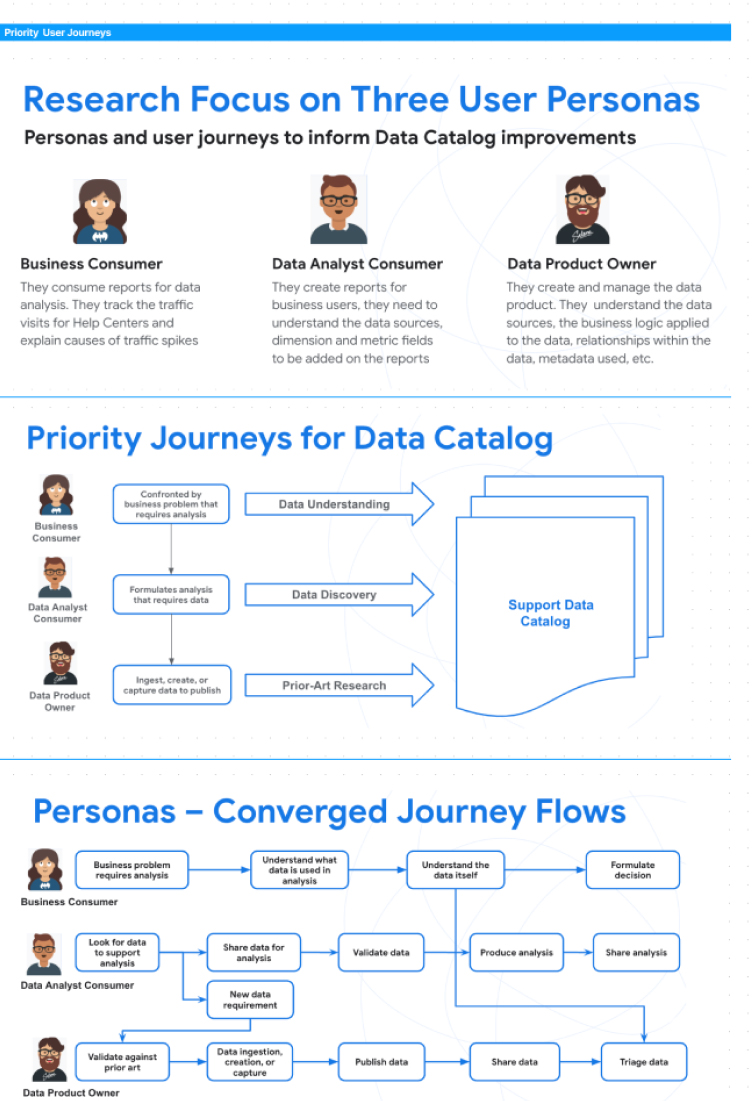
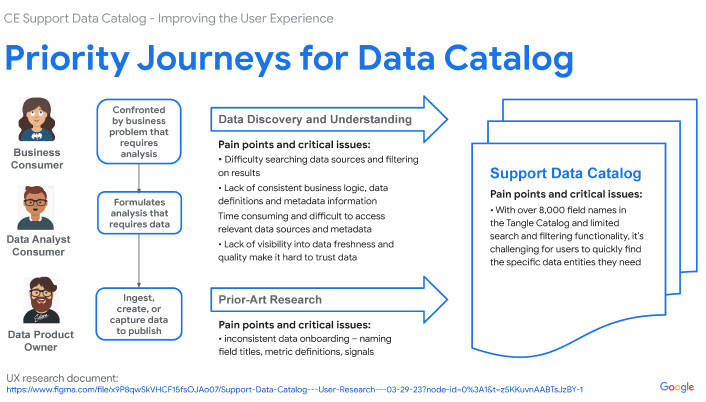
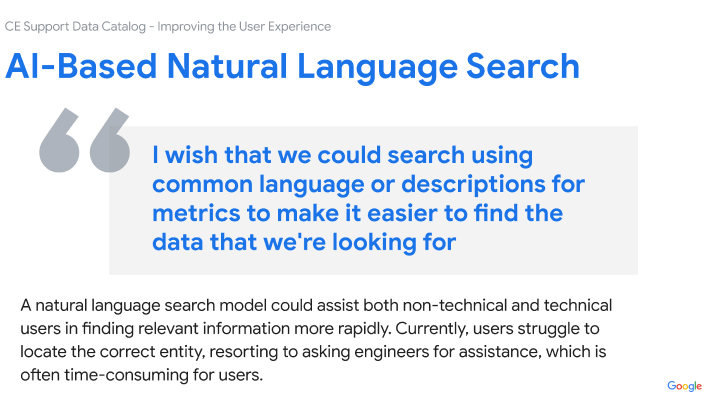
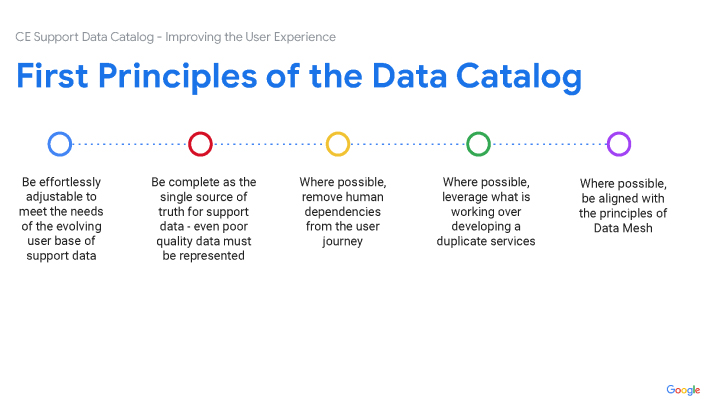
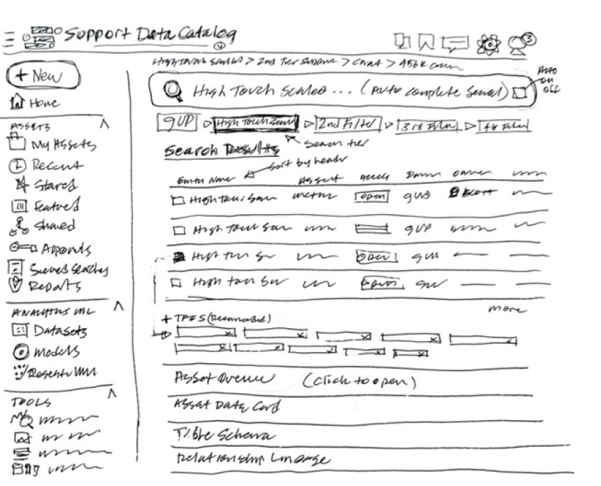
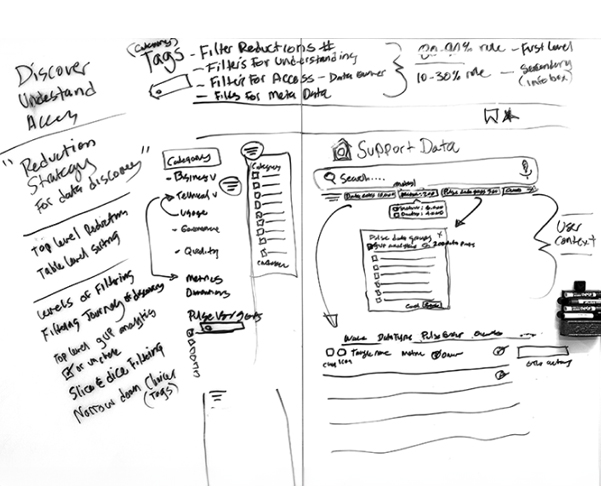
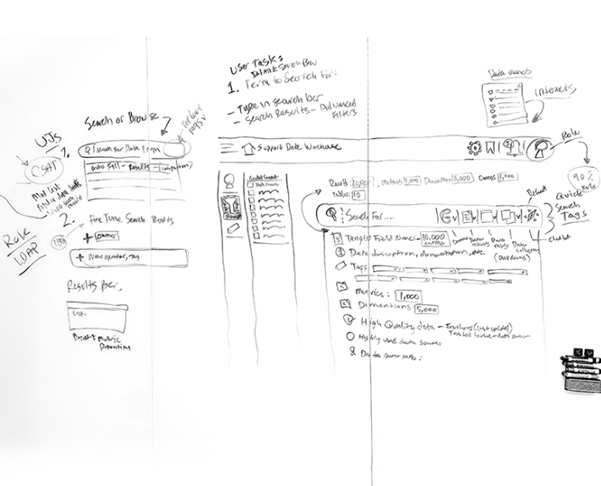
Problem: UX Audit Shows Poor Usability And Data Access
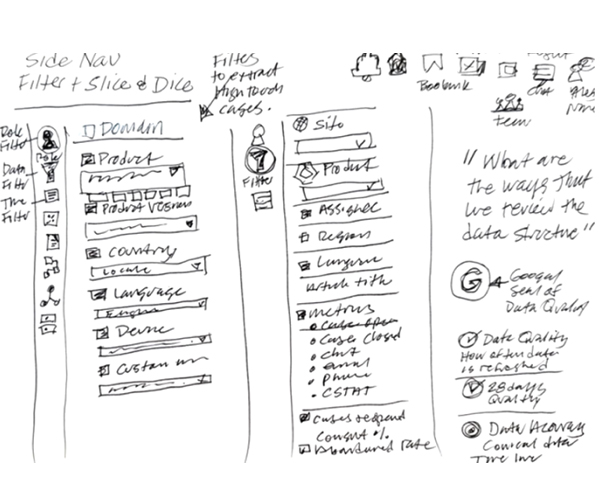
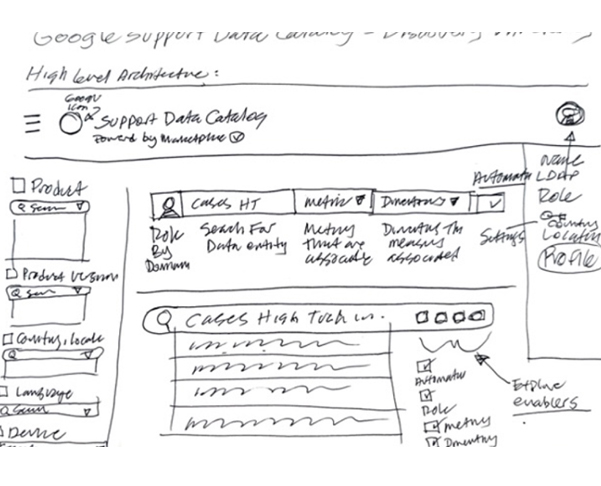
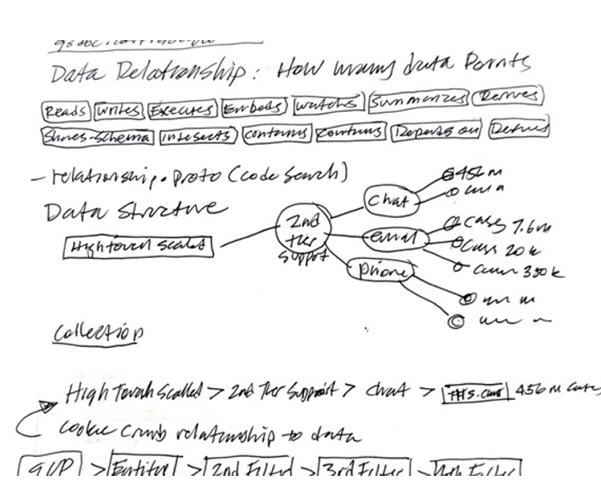
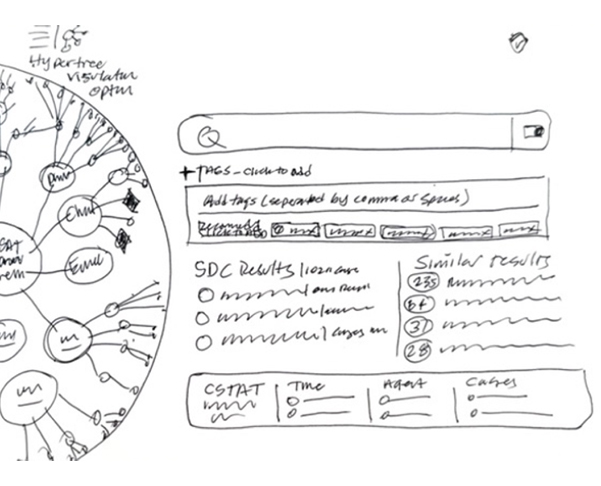
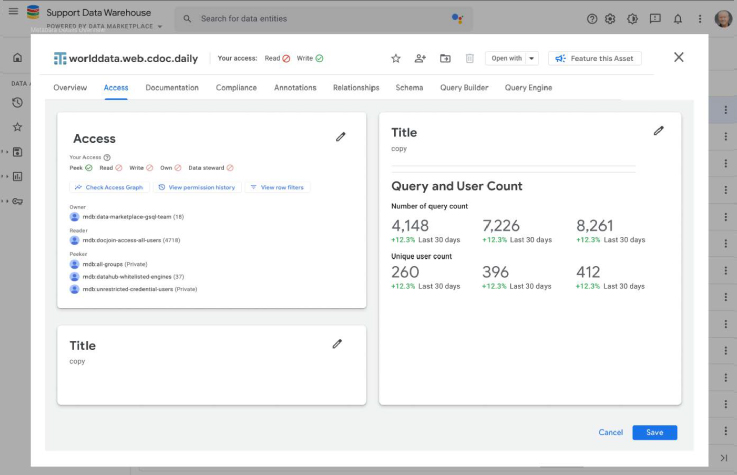
The core challenge lay in the catalog's convoluted usability stemming from a lack of consistent onboarding and uniform documentation across its vast, legacy data repositories. Users were frustrated with an inefficient search experience, compounded by legacy architecture that complicated data discoverability and accessibility. This led to a frustrating user experience for those engaged in customer support reporting, BI analytics and machine learning model development, necessitating a redesign that not only streamlines search functionalities and data organization with generative AI, but also seamlessly integrates machine intelligence into the user flows to alleviate technical and navigational pain points universally.